397 liens privés
Surveillance en temps réel de la production d'électricité de chacune des tranches des centrales nucléaires françaises.
Infos pour chaque réacteur : https://pris.iaea.org/PRIS/CountryStatistics/ReactorDetails.aspx?current=196


Quelques règles pour mettre en place un système d'alerting de la production pertinent dans le cadre d'astreintes 24/24.
Consider "iowait".
Ce chapitre 3 est disponible gratuitement et porte sur Riemann, un excellent outil de monitoring que j'ai adopté au boulot:
https://artofmonitoring.com/TheArtOfMonitoring_sample.pdf


Un petit script bash qui permet de bootstraper les datasources et des templates dans grafana.
Cela consiste à faire des POST sur l'API.
Voir aussi https://github.com/influxdata/kapacitor pour l'alerting.
Cet outil s'appuie sur un datastore influxdb.

Les gens de Grafana bossent sur un proto qui intègre une solution d'alerting à leur outil de monitoring. Aujourd'hui il faut utiliser des solutions externes (Bosun, Prometheus, Riemann, sensu, graphite-beacon....). Ben oui, c'est pas déconnant de vouloir faire le monitoring et l'alerting depuis le même outil comme le fait Zabbix.
C'est en cours de discussion ici: https://github.com/grafana/grafana/issues/2209
Sélection d'outils de monitoring, avec type de déploiement, capture d'écran.
Juste un mot..
Tous les médias ont soulignés les désastres de la pollution atmosphérique, mais peu de personnes semblent prendre conscience de l’ampleur de ce problème. Pourtant la pollution tue, beaucoup. Elle est considérée comme un problème de santé publique majeur selon l'OMS [1] et coûte entre 1 et 2 milliards d'euros à la France chaque année [2]. En France toujours, on compte 42000 morts prématurées par an [3] pour l’exposition aux particules en suspension, toutes sources d’émissions confondues.
Selon un rapport de AirParif [4], la source principale des particules fines inférieures à 2.5µm [5] au niveau du « Boulevard périphérique » de Paris est issue du trafic routier pour 44%. Le contributeur principal pour ce trafic routier est à 90 % issu des véhicules Diesel.
Reconnaitre cette pollution c'est questionner et remettre en cause la politique pro-voiture diesel que les gourvenements successifs nous ont servi pendant des années.
Faudrait surtout pas. Alors on continue, et on met ces problèmes de santé publique sous le tapis: Les département des Hauts de Seine, Seine et Marne, et maintenant des Yvelines coupent des financements à Airparif l'organisme agréé par le ministère de l'Environnement pour la surveillance de la qualité de l'air pour une région de juste .. 12 millions d'habitants.
Mais heureusement, la COPs 21 va nous sauver: https://lut.im/z6ID9DVXnP/imIXjh5S9YNooHnE.jpg:large
[1] Rapport Sénat / OMS https://jeekajoo.eu/links/?nFGk7A
[2] http://www.lefigaro.fr/conjoncture/2015/04/11/20002-20150411ARTFIG00051-la-pollution-de-l-air-coute-entre-1-et-2-milliards-d-euros-par-an-a-la-france.php
[3] http://www.euro.who.int/document/e88189.pdf p92
[4] http://www.airparif.asso.fr/_pdf/publications/synthese_particules_110914.pdf
[5] PM https://jeekajoo.eu/links/?l6MueA

"""
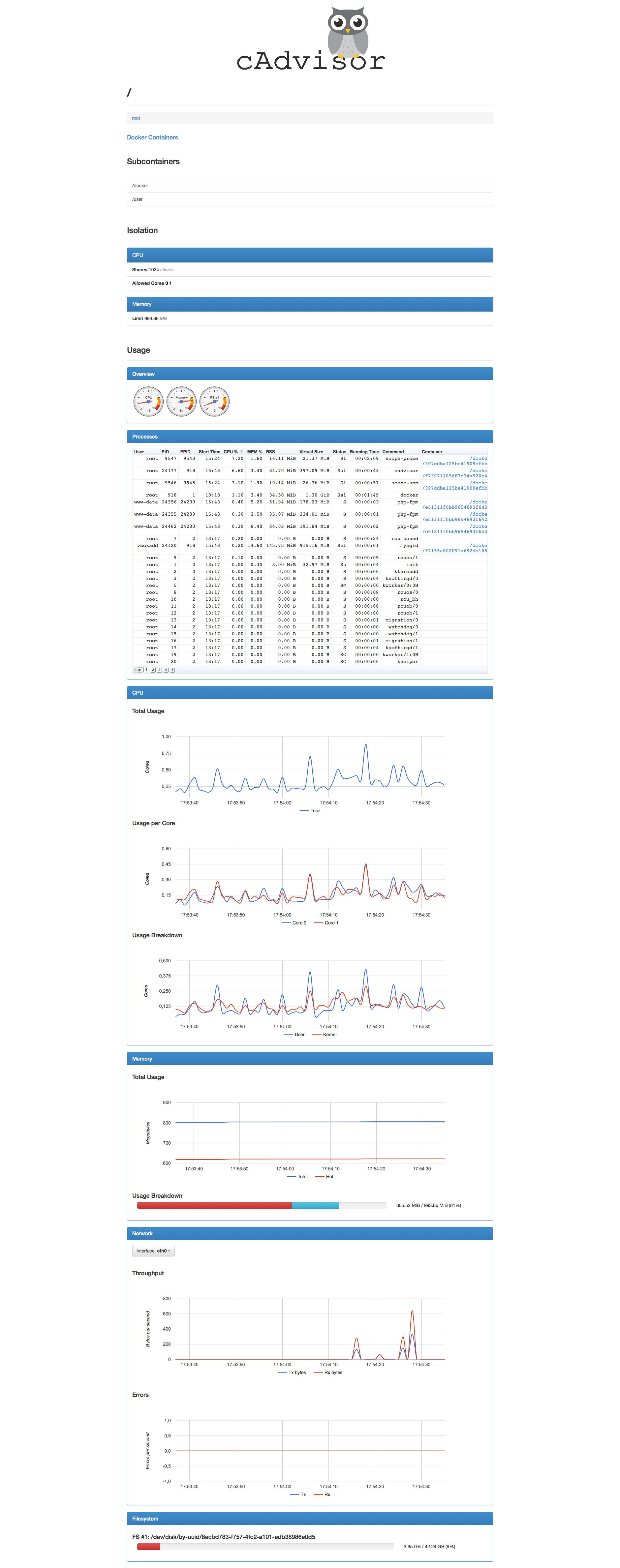
cadvisor - Analyzes resource usage and performance characteristics of running containers.
"""
Un conteneur qui monitore d'autres conteneurs (via les volumes docker).
Ca donne ça: https://wooster.checkmy.ws/assets/img/posts/wordpress-docker/cadvisor.png
Je confirme donc ce que j'ai avancé ici https://jeekajoo.eu/links/?4I4zCw
Les freezes étaient dus aux commandes smartctl.
Vous avez peut-être remarqué que mon serveur a crashé 2 fois: cette nuit à 1h et ce midi vers 12h35.
Le serveur freeze complètement avec l'erreur suivante qui s'affiche sur la console ILO “rcu_sched detected stalls on CPUs/tasks”.
A ce moment il est impossible de se logguer, le serveur est complètement inopérant et il faut rebooter.
Hier soir j'ai mis en place des plugins munin qui check les disques via SMART (cf https://jeekajoo.eu/links/?1rHnoQ) et c'est peut être la cause du problème. Du coup je mets de coté ce thread qui évoque la piste. En attendant, j'ai désactivé les plugins munin qui font ces checks pour voir si c'est ça.
Par exemple pour le crash de ce matin, les logs syslog ne m'aident pas trop. Il y a un gros trou entre 0h59 et 09h03 (le moment où j'ai reset) avec une grosse bousée de caractères dégueux.
"""
Sep 11 00:59:57 sd-48169 kernel: [2806496.321490] FW REJECT (input): IN=eth0 OUT= MAC=ff:ff:ff:ff:ff:ff:28:92:4a:33:65:62:08:00 SRC=195.154.170.38 DST=195.154.170.255 LEN=78 TOS=0x00 PREC=0x00 TTL=128 ID=14896 PROTO=UDP SPT=137 DPT=137 LEN =58 ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@Sep 11 09:03:43 dedibox rsyslogd: [origin software="rsyslogd" swVersion="8.4.2" x-pid="646" x-info="http://www.rsyslog.com"] start Sep 11 09:03:43 dedibox systemd-modules-load[157]: Inserted module 'loop'
"""
Tuto sur 'smartd' (paquet 'smartmontools') pour monitorer les disques et être alerté par mail en cas de défaillance. Pour ma part je délègue le travail à 'munin' qui lance des commandes 'smartctl' régulièrement via cron.
Pour mon RAID hard de 2 disques HP en SATA, je fais lancer ces 2 commandes pour chacun des disques:
smartctl /dev/sda -a -d cciss,0
smartctl /dev/sda -a -d cciss,1
"""
Sibyl System (reloaded) is a free monitoring service for friends and family. If you want to use it, just send an email to vincib and ask for a ssh/git access. you'll be able to configure nagios, pnp4nagios and munin to check your own machines. Email and SMS sending (up to 5/h, 20/d) is available.
"""
Benjamin Sonntag propose de monitorer votre petit serveur gratuitement avec pnp4nagios / munin / nagios. Notifications mail et sms.
Son mail est sur cette page https://benjamin.sonntag.fr/curriculum.php
Présentation de cet outil de monitoring à Monitorama 2015: https://vimeo.com/131581326

monitorer le réseau et voir quelles communications sont faites pour chaque application android.
avec graph.
dispo sur fdroid.

Me gusta mucho!
Sysdig permet d'afficher un spectrogram coloré avec la latence des différents appels systèmes (par ex. open, close, read, write, socket…) pour un programme donné. Cela permet directement de voir, de manière élégante et sans serveur X, dans quel frange de temps de réponse se situent les syscalls qu'on analyse.
Pour mettre en valeur cet outil, l'auteur montre un cas pratique avec un benchmark des différents type de stockage qu'offre EC2: ssd local à l'instance, ebs magnetic, ebs ssd.

{kind=link}
{kind=link}